
Ruby on Rails, like other web application frameworks, requires putting pressure on performance and scalability. As a result, our users (web browsers clients) will not give up and leave the page at the first shot when attempting to, as well as going further through it. To make the application work entirely smoothly we have to take care of a few things – analyzing and optimizing the sql queries, getting rid of the complex conditions, improving the frontend rendering, adjusting the server configuration and so on.
This article should give some suggestions and tips on how to achieve the above goal. Some of these you may have probably already met on your Ruby on Rails adventure, although others, after implementation, can reduce the application’s response time even more.
10 Tried-And-True Ways to Speed Up and Improve Performance of Your Ruby on Rails App
Ruby on Rails, like other web application frameworks, requires putting pressure on performance and scalability. As a result, our users (web browsers clients) will not give up and leave the page at the first shot when attempting to, as well as going further through it. To make the application work entirely smoothly we have to take care of a few things – analyzing and optimizing the sql queries, getting rid of the complex conditions, improving the frontend rendering, adjusting the server configuration and so on.
This article should give some suggestions and tips on how to achieve the above goal. Some of these you may have probably already met on your Ruby on Rails adventure, although others, after implementation, can reduce the application’s response time even more.
SQL query optimization
One of the reasons why your application may be struggling with performance issues is the not-the-best database queries. These are the most common issues which have an impact on the backend efficiency and should be handled as a priority. As a RoR developer you are obligated to have at least some basic database skills in order to examine and keep an eye on the application SQL queries. I have included some points on which you ought to have focused on below.
N+1 and eager loading
This problem concerns redundant query statements while fetching data for the database table. It takes place while retrieving data for its relations by doing additional calls. We can skip extra queries by making up only a single execution. At this point, there are a few helpful options - the includes method, the bullet gem and the strict_loading mode.
Let’s have a look at the following scenario:
class User < ApplicationRecord
has_many :addresses
end
class Address < ApplicationRecord
belongs_to :user
end
We want to retrieve the last address information from each of the users. We can do it in a very bad way and make the additional queries:
User.all.map { |u| u.addresses.last.line_1 }
# SELECT "users".* FROM "users"
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" = $1 ORDER BY "addresses"."id" DESC LIMIT $2 [["user_id", 1], ["LIMIT", 1]]
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" = $1 ORDER BY "addresses"."id" DESC LIMIT $2 [["user_id", 2], ["LIMIT", 1]]
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" = $1 ORDER BY "addresses"."id" DESC LIMIT $2 [["user_id", 3], ["LIMIT", 1]]
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" = $1 ORDER BY "addresses"."id" DESC LIMIT $2 [["user_id", 4], ["LIMIT", 1]]
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" = $1 ORDER BY "addresses"."id" DESC LIMIT $2 [["user_id", 5], ["LIMIT", 1]]
=> ["55670 Bruen Junction Suite 015", "7324 Tyrell Neck Apt. 181", "6097 Connelly Meadows Suite 518", "70357 Ullrich Inlet", "4234 Parker Ferry"]
As you may see above, there are many address queries. This number can be easily reduced by using the includes method, as seen here:
User.includes(:addresses).map { |u| u.addresses.last.line_1 }
# SELECT "users".* FROM "users"
# SELECT "addresses".* FROM "addresses" WHERE "addresses"."user_id" IN ($1, $2, $3, $4, $5) [["user_id", 1], ["user_id", 2], ["user_id", 3], ["user_id", 4], ["user_id", 5]]
=> ["55670 Bruen Junction Suite 015", "7324 Tyrell Neck Apt. 181", "6097 Connelly Meadows Suite 518", "70357 Ullrich Inlet", "4234 Parker Ferry"]
See the point? Fewer queries = less time needed to access the data. This has an impact on the performance and the scalability of the application.
To catch and avoid the N+1 issues, the bullet gem is a helpful tool. This brings up the customizable notifications once the eager loading has appeared. Another great option, introduced in Ruby on Rails 6.1, is the strict_loading mode. We can swiftly implement this by adding the option in the place where we specify the association’s model:
class User < ApplicationRecord
has_many :addresses, strict_loading: true
end
As result, when trying to execute User.first.addresses.first we get an error ActiveRecord::StrictLoadingViolationError.
Inner joins, the foundation of SQL
If you wonder how to pull the records that have an association with another table, then you are thinking about the joins method. This performs the INNER JOIN query and can additionally handle multiple and nested joins as well. So, to present the capabilities, I will create a new model configuration over the previous one.
class User < ApplicationRecord
has_many :addresses, strict_loading: true, dependent: :destroy
has_many :shopping_carts, strict_loading: true, dependent: :destroy
end
class Address < ApplicationRecord
belongs_to :user
end
class ShoppingCart < ApplicationRecord
belongs_to :userhas_many :shopping_cart_items, dependent: :nullify, strict_loading: true
end
class ShoppingCartItem < ApplicationRecord
belongs_to :shopping_cart
end
Bearing in mind the above, it becomes straightforward to execute this query:
User.joins(:addresses, shopping_carts: :shopping_cart_items).distinct
# SELECT DISTINCT "users".* FROM "users" INNER JOIN "addresses" ON "addresses"."user_id" = "users"."id" INNER JOIN "shopping_carts" ON "shopping_carts"."user_id" = "users"."id" INNER JOIN "shopping_cart_items" ON "shopping_cart_items"."shopping_cart_id" = "shopping_carts"."id"
=>
[# <User:0x0000000106d3c6b8 id: 3, name: "John Travolta", age: 66, created_at: Tue, 13 Sep 2022 10:54:22.935341000 UTC +00:00, updated_at: Wed, 14 Sep 2022 09:04:14.747615000 UTC +00:00>,
# <User:0x0000000106d3c5f0 id: 2, name: "Anna Kowalska", age: 51, created_at: Tue, 13 Sep 2022 09:38:54.901001000 UTC +00:00, updated_at: Tue, 13 Sep 2022 09:38:54.901001000 UTC +00:00>,
# <User:0x0000000106d3c528 id: 1, name: "Jan Kowalski", age: 53, created_at: Tue, 13 Sep 2022 09:38:54.799866000 UTC +00:00, updated_at: Tue, 13 Sep 2022 09:38:54.799866000 UTC +00:00>]
This simple ActiveRecord statement pulls out only the users that have an association both with address and shopping_cart_item. Moreover, we can easily limit the result through specifying the related model attributes with where clause, as in the example:
User.joins(:addresses, shopping_carts: :shopping_cart_items).where(shopping_carts: { shopping_cart_items: { price: 90..100 } }).distinct
# SELECT DISTINCT "users".* FROM "users" INNER JOIN "addresses" ON "addresses"."user_id" = "users"."id" INNER JOIN "shopping_carts" ON "shopping_carts"."user_id" = "users"."id" INNER JOIN "shopping_cart_items" ON "shopping_cart_items"."shopping_cart_id" = "shopping_carts"."id" WHERE "shopping_cart_items"."price" BETWEEN $1 AND $2 [["price", 90], ["price", 100]] => [# <User:0x0000000106b24240 id: 3, name: "John Travolta", age: 66, created_at: Tue, 13 Sep 2022 10:54:22.935341000 UTC +00:00, updated_at: Wed, 14 Sep 2022 09:04:14.747615000 UTC +00:00>]
joins along with where are powerful tools, which we should consider implementing in our applications, boosting the performance rapidly.
Bulk queries
Ruby on Rails with ActiveRecord support provides great features which bulk our database queries into a single one. With that, when looping through some set of records and making a separate query for each one, we can become experts and instead use either upsert_all, update_all, insert_all or delete_all. CAUTION: These will not instantiate nor trigger any callbacks. The validations are also skipped, but this inconvenience can be replaced by constraints provided by the database itself. One of the available constraints is checks, but the rest is just as important (Not-Null, Unique, Exclusion, primary and foreign keys). Let’s focus on the first method for now.
Let’s imagine the user had just bought a few items and used a discount code, which means that prices should be updated. Below I attach a code snippet for a better view:
user = User.find_by(name: 'Jan Kowalski')
shopping_cart = user.shopping_cart
shopping_cart.shopping_cart_items.each do |item|
item.update(price: updated_price(item))
end
Performing an update and making a new query per each shopping_cart_item is not the best idea.
Since Rails 6.0, upsert_all method comes to the rescue. It will map the affected records and then use a single query. Thanks to that, we reduce the connection time to the database. Do not forget to add the unique_by option to specify a unique index on the table (supported on postgres and sqlite). This single query inserts multiple records and/or searches for a proper record and updates its price when there is a duplicated name. Example shows:
mapped_items = [{ name: 'Donald Duck', price: 32 }, { name: 'Minnie Mouse', price: 17 }, { name: 'Mickey Mouse', price: 59 }]
ShoppingCartItem.upsert_all(mapped_items, unique_by: :name)
# INSERT INTO "shopping_cart_items" ("name","price","created_at","updated_at") VALUES ('Donald Duck', 32, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP), ('Minnie Mouse', 17, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP), ('Mickey Mouse', 59, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP) ON CONFLICT ("name") DO UPDATE SET updated_at=(CASE WHEN ("shopping_cart_items"."price" IS NOT DISTINCT FROM excluded."price") THEN "shopping_cart_items".updated_at ELSE CURRENT_TIMESTAMP END),"price"=excluded."price" RETURNING "id"
=> # <ActiveRecord::Result:0x000000010d9f17b8 @column_types={}, @columns=["id"], @hash_rows=nil, @rows=[[1], [2], [3]]>
insert_all unlike the previous, only inserts multiple records into the database. Records duplicated by index are skipped. This method is not available for Rails 5.2 and earlier.
Both update_all and delete_all methods are common and generally known. We use them with the ActiveRecord_Relation instances. The first one updates a set of records with certain attributes, whereas the next performs a DELETE statement.
Find_each, items in batches
When iterating over an enormous amount of records, there is a great opportunity to use the find_each. It works pretty much the same as each method, except it will create batches and do the query for each of them. Implementation of find_each results in better memory management, thereby increasing the performance.
each loads the scope once, as in the following example:
User.where(age: 33..66).each {}
# SELECT "users".* FROM "users" WHERE "users"."age" BETWEEN $1 AND $2 [["age", 33], ["age", 66]]
On the other hand, we can slash that into smaller batches. The default limit of the records is 1000, and this value can be replaced with batch_size option as below:
User.where(age: 33..66).find_each(batch_size: 2000) {}
# SELECT "users".* FROM "users" WHERE "users"."age" BETWEEN $1 AND $2 ORDER BY "users"."id" ASC LIMIT $3 [["age", 33], ["age", 66], ["LIMIT", 2000]]
Pluck vs map
pluck runs a query to the database and returns an Array with only these attributes we mark in. It is much more efficient than pulling all the record information. Especially for a large number of records.
In places where map or collect is being used, we can often consider replacing it with pluck. Both of these methods load entire objects when performed upon the ActiveRecord_Relation. Let’s focus on the following for a moment:
User.pluck(:name)
# SELECT "users"."name" FROM "users"
User.all.map(&:name)
# SELECT "users".* FROM "users"
When focusing only on the SQL queries, it turns out the pluck statement is a winner and is more efficient. With each new record, the differences will become more and more visible.
SELECT clause
Rails select method modifies the database query and limits the result to the fields we have specified. It accepts string or symbol attributes as parameters. Hereby, the query response volume is significantly reduced, so the performance increases highly. The difference is much more noticeable when executing complex queries, for example when retrieving data from multiple tables. In comparison with the includes method, select is more efficient because Rails doesn’t have to instantiate the associations.
User.all
# User Load (0.4ms) SELECT "users".* FROM "users"
User.all.select(:name)
# User Load (0.4ms) SELECT "users"."name" FROM "users"
Add indexation
Definition
Object-relational databases provide indexes for table column(s). An Index is a data structure, helpful when we intend to pull certain data from the database in the shortest time possible. It also concerns the following cases:
- the queries we would run often
- indexed columns that are being triggered in either where, having or order_by clauses
- when creating table associations (belongs_to or has_many)
Imagine indexes as shortcuts in the operating system. You place them either on the desktop, on a certain deck/sidebar, or in any other space you can access very quickly when willing to. These shortcuts may also have been grouped somehow according to their purpose – entertainment, workspace etc. On the other hand, you can open a file browser and search for a particular asset or an application. It can take a long time to scan all the files through.
Spaces to apply
Any unique search should be wrapped in indexes. On websites, we have search engines, which the user fills in by e.g. strings. Under the hood, the queries may look like this:
Book.find_by(title: 'The Great Gatsby')
Book.find_by(author: 'Fitzgerald')
Another situation concerns table relationships. In our framework specified by belongs_to or has_many methods. As for the second, it includes polymorphic associations as well. For these cases we add indexes for foreign keys, as in the example:
class User < ApplicationRecord
has_many :shopping_carts, dependent: :destroy
end
class ShoppingCart < ApplicationRecord
belongs_to :user
end
And schema.rb file should contain appropriate information:
create_table "shopping_carts", force: :cascade do |t|
t.index ["user_id"], name: "index_shopping_carts_on_user_id"
(...)
For situations when we ought to prevent the creation of duplicate values, we are obligated to add the index. Moreover, frequently used inquiries should be also wrapped in indexes. Look for the sorting occurrences as well.
How to create
We can generate indexes or add them manually. As for the first, we add the index option when running a command:
rails g migration AddSubTitleToBook subtitle:string:index
It has created the migration:
class AddSubTitleToBook < ActiveRecord::Migration[7.0]
def change
add_column :books, :subtitle, :string
add_index :books, :subtitle
end
end
At any time we can add an index to any column with migration by adding the following:
add_index :table(s), :column
On larger tables, since the write access is locked during the index creation process, it might be obligatory to add algorithm: :concurrently as an option. This way we can avoid the downtime issue when a new index is being saved. disable_ddl_transaction! stands for running the migration without a transaction:
class AddIndexOnEmailToUsers < ActiveRecord::Migration[7.0]
disable_ddl_transaction!
def change
add_index :users, :email, algorithm: :concurrently
end
end
It’s worth knowing that we can make the index unique. As result, when migrations are applied, the ActiveRecord will prevent the creation of duplicated columns and throw an error. See the example below:
add_index :books, :subtitle, unique: true
Is it really needed?
At the beginning of the project, with fewer records in the database, the effects of index optimization may not be spectacular. When the application starts to grow, and will be reaching millions of records in tables, then the appropriate indexation is a must-have improvement. The performance differences will become significant.
Applying an index to all columns is not the best practice. It was designed for only those that meet the above criteria. Otherwise, the database will be filled in with redundant index data and the performance will decrease for the columns we (as well as the customers) care about.
Memoization
When we utilize some portion of the logic in the models frequently (or at least twice), it is a good time to consider applying a memoization pattern on the instances of Classes. This way, we can store complex results or big amounts of data within the cache memory and access this data very quickly. Let’s look at the application examples below:
def response
SomeApiClient.new(request_params).call
end
def current_user
User.find_by(id: json_web_token['user_id'])
end
The first method will make a request to the external API. Presumably, it can include some complex operations. The
second one (current_user) is frequently used in our
ApplicationController(s). Both can be memoized, so that the logic will not be performed once again. For instance, the
external API call will not be triggered, and the user query will not be executed. Memoization examples are attached
below:
def response
@response ||= SomeApiClient.new(request_params).call
end
def current_user
@current_user ||= User.find_by(id: json_web_token['user_id'])
end
By adding the instance Class variable (its name should be the same as the method’s name) with the “||=” operator, we have successfully injected the memoization. From now on, when a method is executed once again, it returns “cached” data only.
Full-text search
FTS comes with help when searching for some text in table columns within the database. Similar to standard search, the query results consist of the matched words. However, the full-text search, in addition, will return records, which include only a part of the searched phrase.
MySQL and Postgresql databases provide their own support for full-text indexing and searching. The first one introduced the FULLTEXT type index with searching performed by using MATCH() AGAINST(). The second, Postgresql, added the GIN index and to_tsquery method.
For postgres projects, the pg_search can be applied additionally. It is easy to set up and does not require any separate processes/callbacks. Moreover, it provides multiple searching techniques and enables a powerful query DSL. Thus, in most cases, it should satisfy the requirements for the full-text search.
When the main focus is on high efficiency, I recommend the ElasticSearch engine, which I would like to briefly introduce in this article. To integrate it with the ActiveRecord-based model you need to have an ElasticSearch cluster running. The elasticsearch-model gem is required, but elasticsearch-rails and elasticsearch-persistence also provide great facilities.
To wrap a model with searching functionality firstly you need to include Elasticsearch::Model module:
require 'elasticsearch/model'
class Article < ActiveRecord::Base
include Elasticsearch::Model
end
You may also put in all the Elasticsearch-related logic in a concern. This option is recommended and more common:
# app/models/concerns/searchable.rb
module Searchable
extend ActiveSupport::Concern
included do
include Elasticsearch::Model
mapping do
# schema definition described here
end
def self.search(query)
# block defines a search for all indexed fields
end
end
end
I will limit myself and describe only a couple of the many useful and powerful Elasticsearch features. The first one
is self.search(query). Inside it, the user adds specific conditions to a search definition, eg. the size of
the returned records, setting an empty query when using the dynamic Query DSL. Matching query logic is also included –
you can easily define the number of typos after which the query result still matches. Finally, complex filters can be
defined in the search function (you may also add additional parameters as shown below).
def self.search(query, gender = nil)
(...)
filter: [
{
term: { gender: gender }
}
]
(...)
end
The next feature I would like to describe is the mapping block. It is a place where the user describes
the structure of the document and its indexed fields. Hence, regarding the full-text search, you should list all of
the fields with text type – the fields can be queried using the FTS method. Another common type is the keyword, which
is used in filters.
mapping do
indexes :author, type: :text
indexes :title, type: :text
indexes :publication_year, type: :keyword
end
But how to enforce the ElasticSearch data to be up to date after we create, update or delete the record in
ActiveRecord? In this case, we can benefit from Elasticsearch::Model::Callbacks. It will ensure that the indexed data gets updated
accordingly. Just inject it into the searchable object:
included do
include Elasticsearch::Model::Callbacks
end
Performance profilers
For a better and much more convenient way to catch performance issues, we use the profilers. These applications provide statistics of pages rendering time, consuming sql queries, memory leaks and much more. Additionally, profilers may serve as an alert monitoring tool.
Monoliths
In the case of monolith applications (still very common), which serve both the frontend and backend layers in a single codebase, a great profiler to recommend is rack-mini-profiler. This set of gems works in development as well as in production. The core feature is database profiling (it supports mysql and postgres for sure). Also, it provides a flame graph chart, which indicates time spent by gems/libs during application activity.
For RoR projects, after the gems have been fetched and bundled, the user can start profiling his application. When jumping through the pages, you will spot the button at the top left, indicating the time needed to render the view. Once clicked, it will display some details covering the page load. Here you can catch any redundant server activity, which consumes the user's time. Example view containing details:
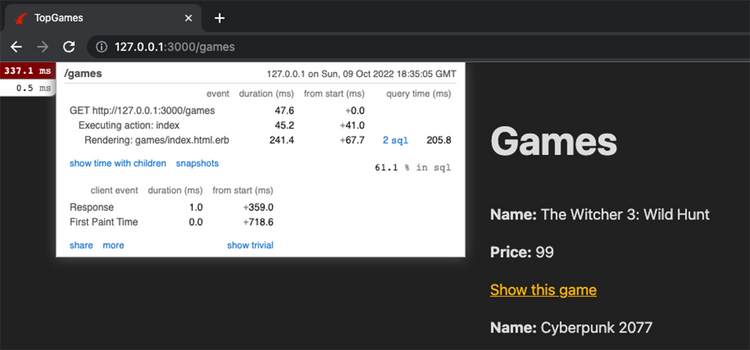
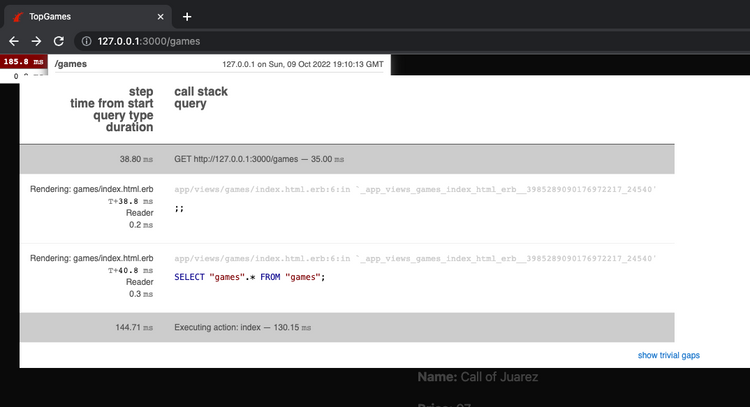
But it is not over yet – if database queries have appeared, then you can easily find out more about them in the call stack query tab. It's a great space for pure sql query fans as it contains all the information.
Moreover, other exciting features included in the rack-mini-profiler set are memory_profiler and stackprof. The first one brings in memory utilization data with the division into files, locations, classes and gems. This can be viewed by adding additional parameters to the url (“?pp=profile-memory”) and entering in. Eg. “http://localhost:3000/games?pp=profile-memory”.
Finally, the stackprof allows us to present the whole stack on graphs. You can generate it just like before by appending the “?pp=flamegraph”.
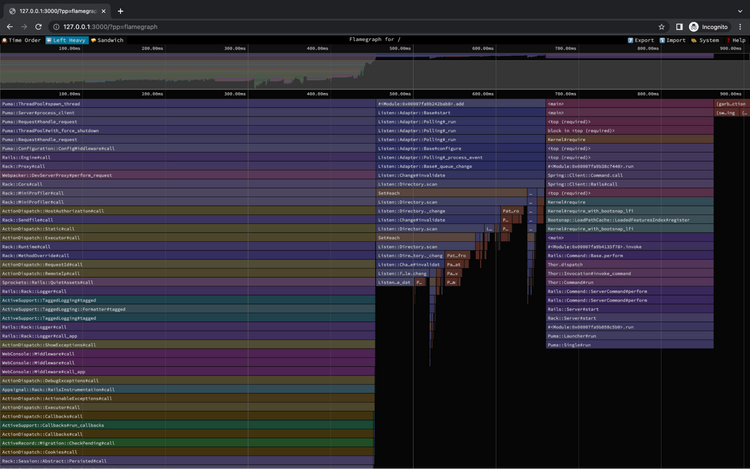
Microservices
Profiling microservices-based apps can be a great achievement. For those, multi-tool monitoring applications were designed (they can handle monoliths as well). They provide metrics for application performance monitoring, infrastructure troubleshooting, full log management, page loading time and many others. Additionally, the alert system in case of any failures is also noteworthy.
New Relic, Scout APM and DataDoG are popular choices. They provide all the facilities mentioned above. Monitoring applications have a free tier plan available as well, so users can take these for a test drive.
Conclusions
Even though Ruby on Rails puts more emphasis on a swift delivery process than on exposing super quick API and lightning-fast rendering pages, we must continuously optimize the server activity and try to avoid performance issues.
To not disrupt the User Experience we should seek to meet the time frame targets in our applications. According to the principles included in the article “Response Times: The 3 Important Limits”, the user’s attention will stay focused if the delay takes less than 1.0 seconds. If we score above this, we should definitely consider ways of reducing that time.
In my article, I have made some suggestions to make the page content loading faster since the backend responds more efficiently. As a side effect, the implementation will result in less resource consumption, so the scalability will improve and the costs should be reduced.
The list of tips is constantly evolving. New performance enhancements are added and those that already exist are updated. Users should keep track of that process and make Ruby on Rails projects as efficient as they can.
Stay tuned for the next part of the article!
On-demand webinar: Moving Forward From Legacy Systems
We’ll walk you through how to think about an upgrade, refactor, or migration project to your codebase. By the end of this webinar, you’ll have a step-by-step plan to move away from the legacy system.

Latest blog posts
Ready to talk about your project?
Tell us more
Fill out a quick form describing your needs. You can always add details later on and we’ll reply within a day!
Strategic Planning
We go through recommended tools, technologies and frameworks that best fit the challenges you face.
Workshop Kickoff
Once we arrange the formalities, you can meet your Polcode team members and we’ll begin developing your next project.