
Most systems and applications nowadays provide ways to generate reports. Ask any programmer, and they likely have experience working with reporting logic code, aggregating statements in Excel or saving data snapshots into a CSV file. However, it’s common that the code found—or even created ourselves—was either unfriendly to read, broke SOLID/DRY principles, or lacked any object patterns.
Ruby on Rails: How to Keep Report Generation Logic Simple and Clear
Most systems and applications nowadays provide ways to generate reports. Ask any programmer, and they likely have experience working with reporting logic code, aggregating statements in Excel or saving data snapshots into a CSV file. However, it’s common that the code found—or even created ourselves—was either unfriendly to read, broke SOLID/DRY principles, or lacked any object patterns.
Controlling reporting logic from the very start goes a long way to make programming life easier. The most common headache stems from poor design assumptions. From the beginning of the project, we know if a system or app is required to generate one or more reports.
At this stage, we should already be thinking about code planning. This allows us to handle many reports in the future, not just the early ones.
In this article, I want to present a universal solution to control reporting logic using Ruby, for projects at the beginning of their run, and also for existing applications. We’ll be creating a layer of abstraction to make sure our current and future code is legible, clear and easy to maintain.
A Real-world example
When it comes to report generation logic, programmers frequently throw together a “fast” solution—lumping logic into one class called asynchronously by the job/worker. Little do they know, they’ve created a technical debt from the very beginning!
A recent project I worked on provides a great case-study for the benefits of refactoring.
The application was under development for 9 years, mainly as a hobby (and by interns). The reports were very important for the client, but during their creation, there were often errors (mainly due to lack of data), and modification of their content was associated with many hours of analyzing old and unreadable code. In order to help the client, we decided to refactor the reports and resolve any bugs, instead of adding more lines to the unreadable code.
Each report looked similar at first in its design, but differed in complexity and number of nests, as shown below:
class SomeCSVWorker
include Sidekiq::Worker
sidekiq_options queue: 'package_import'
def perform(id)
# previously implemented class for storing reports
export = Export.find(id)
require 'csv'
csv_file = ''
# CSV generation algorithm
csv_file << CSV.generate_line(%w[ID Some Attributes])
# sample data
SomeResource.where('created_at >= ?', Time.now - 1.month).each do |res|
csv_file << CSV.generate_line([res.id, res.some. res.attributes])
end
# temporary file generation
file_name = Rails.root.join('tmp', 'resource-name_timestamp.csv')
File.open(file_name, 'wb') do |file|
file.puts csv
end
# S3 File upload
s3 = Aws::S3.new
key = File.basename(file_name)
file = s3.buckets['bucket-name'].objects["csvs/#{key}"].write(file: file_name)
file.acl = :public_read
# storing S3 file path to AR instance
export.update(file_path: key)
end
end
Originally, the logic of report generation was done in the Sidekiq worker code. This has several consequences:
- The DRY rule is violated here several times. Repetitive code is responsible for adding a report to the S3 bucket, generating it or updating an instance in ActiveRecord.
- The Single responsibility principle is also broken – a worker should only be responsible for performing a certain activity asynchronously, not to define the logic of that activity.
- The open-closed principle is also violated – report logic is open for modification
The first problem that will occur is that changing a single algorithm step causes huge changes in all files. For example, implementing another way to generate a CSV file (such as switching to another library) requires the programmer to change the same lines in all report files.
Even more importantly, let’s assume that we will somehow change the Export table (e.g. the file_path column). Again, the change must involve a large number of files, and thus have a higher chance of spoiling something along the way.
As for now, a few code fragments can be moved to higher layers of abstraction, and the report logic could also be moved to a separate class (i.e. service object would be beneficial here).
Planning the refactoring
First off, the general design of the service responsible for generating reports should be taken into consideration. To simplify, only the CSV reports will be analysed:
# frozen_string_literal: true
class CsvReportGeneratorServicedef initialize(export:)@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file; end
def upload_report_to_s3; end
def update_export_path; end
end
Next, a suitable test can be prepared:
describe CsvReportGeneratorService do# We use VCR in our projects to connect with S3
describe '#generate', :vcr dolet(:export) { create :export }
let(:csv_generator) { CsvReportGeneratorService.new(export: export) }
let(:client) { Aws::S3::Client.new }
let(:report_file) { client.get_object export.file_path }
let(:csv_file_data) { CSV.parse report_file }
let(:csv_expected_data) { [] } # Here we may define expected data
before { csv_generator.generate }
it 'generates report' do
expect(report_file).not_to be_nil
expect(csv_file_data).to eq csv_expected_data
end
end
end
Furthermore, the Sidekiq’s Worker class can also be reduced into:
class CsvReportGeneratorWorkerinclude Sidekiq::Worker
sidekiq_options queue: 'reports'
def perform(id)
export = Export.find(id)
csv_generator = CsvReportGeneratorService.new(export: export)
csv_generator.generate
end
end
With the corresponding test:
describe CsvReportGeneratorWorker dodescribe 'worker queueing' do
let(:report_generator_worker) { CsvReportGeneratorWorker.perform_async }
it 'enqueues the job' do
expect { report_generator_worker }.to change(CsvReportGeneratorWorker.jobs, :size).by 1
endend
end
We may now create a block diagram to plan the design of the CsvGeneratorService class:

Uploading a file to S3 and updating the Export record will look the same for each report. We may assume that the logic behind those two functions would be shared among the code. However, the generated data may naturally vary between the reports, and this will be the main topic of the article. Therefore, I have prepared three design patterns that might help clarify the code responsible for report data generation.
Template Method
The Template Method is very common in Ruby, letting us encapsulate parts of the code according to the DRY principle. This pattern provides a skeleton of the algorithm (parent class) and leaves the implementation of individual steps to the inherited classes.
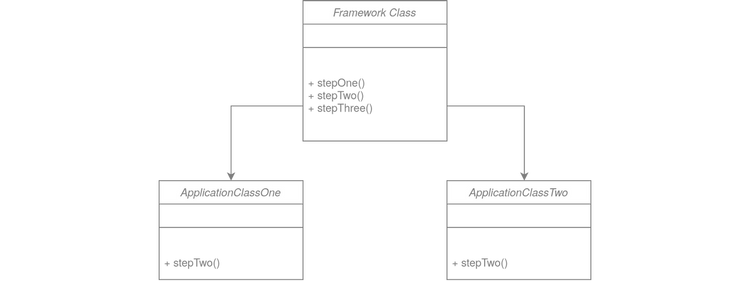
In terms of report refactoring, this method will allow us to encapsulate the part responsible for generating data to the CSV file.
Factory Pattern
Fabrication is a creative pattern that lets us create objects of different classes using a defined interface without revealing their logic. In other words, by using a one-base class, we can create individual classes by implementing a given step/algorithm—in this case, it will be the code responsible for generating data.
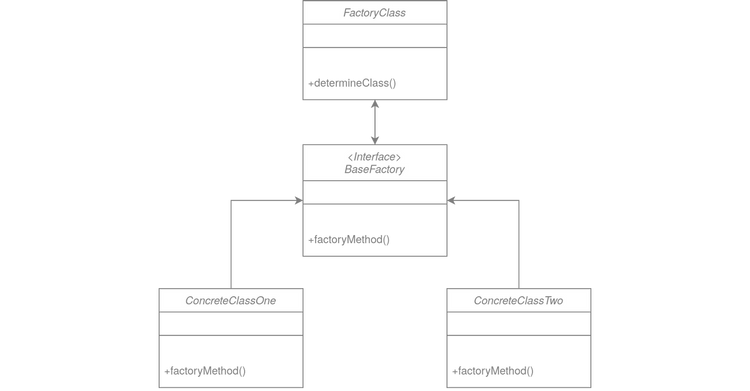
Strategy Pattern
If you’re programming in Ruby on Rails, you may have been dealing with a Pundit gem to manage permissions in your application. The Strategy Pattern, or Policy Pattern, is used to create permissions and is based on composition. This allows us to encapsulate the algorithm in given classes, called strategies. Individual strategies can be invoked in context.
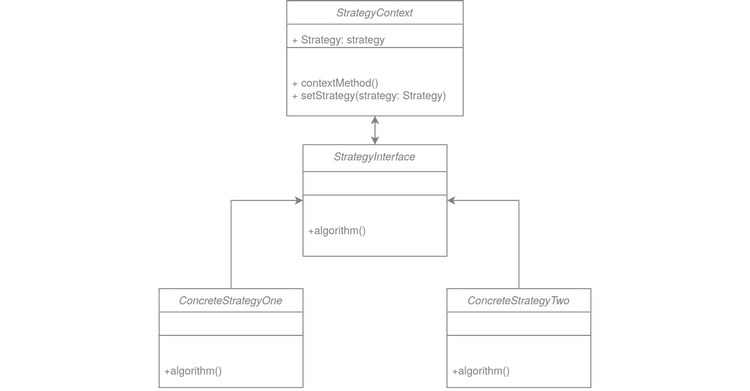
AaaDifferent report types can constitute specific strategies and implement data generation into the report.
Patterns in action – implementing the solution
Now, it is the time to turn theory into practice. Using each pattern, a data generation implementation for a particular report class can be presented.
Template Method
To continue with the TDD convention, let’s start with writing a test case for our future report class, that should become green at the end of implementation:
describe SomeReport do
describe '#generate_report' dolet(:csv_data) { [] } # we can pass CSV data as an empty array# We expect below data in our reportlet(:expected_data) { [['headers'], ['report_body']] }let(:report_class) { SomeReport.new(csv_data) }
before { report_class.generate_report }
it 'generates correct data' do
expect(csv_data).to eq expected_data
endend
end
We expect SomeReport class to eventually return the report data in the expected_data function call that we can save to the report. Let’s define the template:
class TemplateClassCsvdef initialize(csv)@csv = csvend
def generate_reportadd_headersadd_report_rowsend
private
attr_accessor :csv
def add_headersraise NotImplementedErrorend
def add_report_rowsraise NotImplementedErrorend
end
According to the template pattern, each class inheriting from TemplateClassCsv will implement its headers and report content (it may eventually also implement its generate_report method). For our sample report we get:
class SomeReport < TemplateClassCsvprivate
def add_headerscsv << ['headers']
end
def add_report_rowscsv << ['report_body']
end
end
At this point, our test is green, and we can add every subsequent report similarly. It is worth noting that to use a class in our service, we have two options:
- Add the logic responsible for creating the report and upload it to the S3 bucket to TemplateClassCsv, and then call the report using the inheritance class, which will perform the steps of the algorithm correctly. However, this violates the principle of single responsibility
- Add a mapper which, based on the report_key, will call the appropriate inheritance class, which can also be achieved by fabrication in a more readable way.
Factory Pattern
Again, we start by writing a test. The fabrication pattern requires us to start implementation by creating a factory responsible for creating specific report classes. To keep the code legible, let’s recognize that the method responsible for creating a class based on the report key will eventually be called for:
describe CsvReportFactory do
describe '.for' do
context 'some_report' do
let(:report_key) { :some_report }
let(:expected_report_class) { SomeReport }
it 'returns correct class' do
expect(CsvReportFactory.for(:some_report)).to eq SomeReport
endendend
end
The report itself and data generation should also be tested, however, we can use the previously written test—our factory returns the SomeReport class—which will also generate the report using the generate_report method. The implementation of the factory is very simple:
class CsvReportFactory# we can eventually move below code to the other class, like CsvReportErrors# and use something like CsvReportErrors < StandardError and# NoReportKeyProvided < CsvReportErrorsclass NoReportKeyProvided < StandardError; end
def self.for(key)
raise NoReportKeyProvided if key.blank?
key.classify.constantize
end
end
The SomeReport class can now be called in the service with:
class CsvReportGeneratorServicedef initialize(export:)@export = exportend
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file
CSV.generate do |csv|
report_generator_class = CsvReportFactory.for(export.key).new(csv)
report_generator_class.generate_report
endend
def upload_report_to_s3; end
def update_export_path; end
end
Strategy Pattern
By refactoring the code, I also faced the previously mentioned Strategy Pattern, which can also be used to handle reports. We would need a context that supports the selection of the appropriate strategy and a specific strategy to execute our report data generation. Nevertheless, we stick to the TDD approach and start with another test case:
describe CsvReportContext do
describe '#determine_strategy' do
context 'some_report' dolet(:report_key) { :some_report }
let(:csv_report_context) { CsvReportContext.new(report_key) }
let(:strategy_class) { csv_report_context.determine_strategy }
it 'returns correct strategy class' doexpect(strategy_class).to eq SomeReportStrategyendendend
end
describe SomeReportStrategy
describe '.generate_report' dolet(:csv_data) { [] }
let(:expected_data) { [['headers'], ['report_body']] }
before { SomeReportStrategy.generate_report(csv_data) }
it 'generates correct data' doexpect(csv_data).to eq expected_data
endend
end
We can expect that the context based on the report key will return an appropriate strategy implementing the generate_report method, which takes an array as an argument and enters data into it. Starting from the context:
class CsvReportContextdef initialize(report_key)@report_key = report_key
end
def determine_strategy
report_key_based_strategy
end
private
attr_accessor :report_key
def report_key_based_strategy
raise NoReportKeyProvided if report_key.blank?
case report_key
when :some_report then SomeReportStrategy
when :other_report then OtherReportStrategy
else raise InvalidReportKey
endend
end
We can move on to implementing the strategy:
class SomeReportStrategy
def self.generate_report(csv)
add_headers(csv)
add_report_rows(csv)end
def self.add_headers(csv)
csv << ['headers']end
def self.add_report_rows(csv)
csv << ['report_body']end
end
Which would be used in the Service class as follows:
class CsvReportGeneratorServicedef initialize(export:)@export = exportend
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file
CSV.generate do |csv|
report_strategy = CsvReportContext.new(export.key).determine_strategy
report_strategy.generate_report(csv)
endend
def upload_report_to_s3; end
def update_export_path; end
end
The chosen solution
Eventually, we went with a variant with fabrication in our project. Our pick was motivated by the target architecture planned to be used in future (reports with various extensions in one service). At this point, we obtained a clear service to handle CSV reports:
class CsvReportGeneratorServicedef initialize(export:)@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export, :path, :csv
def write_to_csv_fileCSV.generate do |csv|
report_generator_class = CsvReportFactory.for(export.key).new(csv)
report_generator_class.generate_report
@csv = csv
endend
def upload_report_to_s3# uploader was also refactored, upload_file_to_s3# returns path to the file on S3 bucket
s3_uploader = CsvReportGeneratorService::S3Uploader.new(csv)
@path = s3_uploader.upload_file_to_s3
end
def update_export_path
export.update(status: :finished, file_path: path)
end
end
The code has become universal and legible, while the number of workers has been limited to one, created at the very beginning of our refactorization – the corresponding test lights up green and the refactorization is completed.
Summary
At the end of the refactoring process, we were able to achieve the following:
- Universal application – the above logic can be used in different projects and at different stages of their life cycle
- Readability and good practices – our service has about 50 lines of code, kept in one file
- Future-proofing – using a step-by-step approach we know how to refactor the report code at different stages of the project, for different code sizes.
- A simple queuing solution – whether we use Resque or Sidekiq, our main worker and inherited workers (for each report) can look like this:
class ReportGeneratorWorkerinclude Sidekiq::Worker
def perform(id)
report = Export.find(id)
csv_generator = CsvReportGeneratorService.new(export: export)
csv_generator.generate
end
end
- Preserved open-closed principle – each class can be modified freely (in terms of functionality of a given library for a given report extension), without affecting the implementation and functioning of other classes
- Ability to implement SQL views (often forgotten) – which allow to speed up report generation (in our case, holding indexed views helped to reduce generation time by about 20% for large reports)
- Low entry threshold and, consequently, lower costs for the client – a programmer starting to work on reports (after familiarizing himself with their implementation) when adding a new report only has to add his class responsible for generating data, after preparing an appropriate test.
On-demand webinar: Moving Forward From Legacy Systems
We’ll walk you through how to think about an upgrade, refactor, or migration project to your codebase. By the end of this webinar, you’ll have a step-by-step plan to move away from the legacy system.

Latest blog posts
Is Your E-commerce Business Ready for the European Accessibility Act?
Jun 16, 2025 by Janusz Toczko
Legacy Software and Security Risks: Why Regular Audits Are Your Best Defense
Jun 4, 2025 by Jerzy Zawadzki
Magento Enters the SaaS Arena: What Adobe Commerce as a Service Means for Your Business
Apr 24, 2025 by Jerzy Zawadzki
Ready to talk about your project?
Tell us more
Fill out a quick form describing your needs. You can always add details later on and we’ll reply within a day!
Strategic Planning
We go through recommended tools, technologies and frameworks that best fit the challenges you face.
Workshop Kickoff
Once we arrange the formalities, you can meet your Polcode team members and we’ll begin developing your next project.